O modelo foi aprovado em produção. Passou nos testes. A área de TI fechou o chamado.
Seis meses depois, o índice de inadimplência subiu.
A taxa de falsos positivos no antifraude dobrou.
O modelo de precificação começou a errar sistematicamente em determinadas regiões.
Ninguém ligou os pontos. Ninguém conectou a degradação ao modelo.
Isso é drift. E ele já está acontecendo em algum sistema da sua empresa agora.
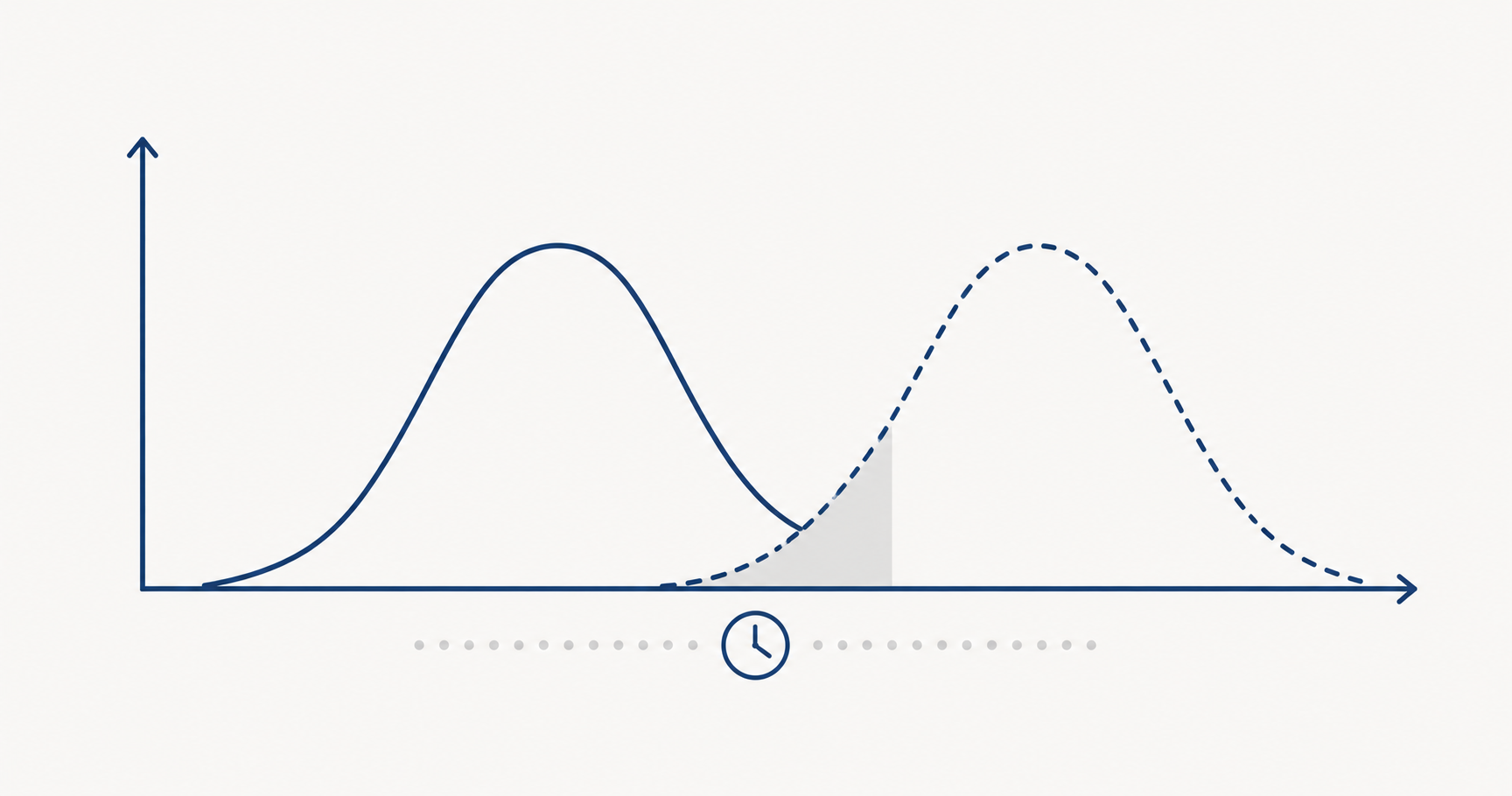
O que é drift — em linguagem de negócio, não de TI
Drift não é bug. Não é falha de código.
É o desalinhamento progressivo entre o mundo que o modelo aprendeu e o mundo em que ele opera agora.
Um modelo de crédito foi treinado com dados de 2021. O perfil do tomador mudou. O modelo não sabe disso. Ele continua aplicando os pesos de 2021 sobre uma realidade de 2025.
Um modelo de detecção de fraude foi calibrado antes do Pix. O comportamento transacional mudou radicalmente. O modelo não foi retreinado. Ele gera mais alertas onde não deveria e menos onde deveria.
Drift não é a IA "quebrando". É a IA sendo precisa — sobre um mundo que não existe mais.
Existem dois tipos que importam para quem decide:
Data drift: o perfil dos dados de entrada mudou. As variáveis que o modelo recebe hoje são diferentes das que ele usou no treino.
Concept drift: a relação entre as variáveis e o resultado mudou. O que era indicador de bom pagador em 2022 não é mais o mesmo sinal em 2025.
Os dois degradam performance. O segundo é mais perigoso porque é menos óbvio.
Por que é silencioso
Drift não dispara alerta. Não aparece no dashboard de erros. Não gera ticket no Jira.
O modelo continua rodando. Continua devolvendo respostas. Do ponto de vista operacional, tudo funciona.
O que muda é a qualidade das respostas — de forma gradual, incremental, dentro da banda de variação que ninguém questiona.
Um modelo que aprova crédito com 92% de acurácia começa a operar com 87%. Depois com 83%. A linha no gráfico cai devagar. Nenhum ponto individual parece alarmar.
E o problema maior: os efeitos de drift aparecem em métricas de negócio — inadimplência, custo de fraude, taxa de conversão — não em métricas técnicas. O CFO vê o número ruim na DRE. Não sabe que a causa é o modelo que ninguém monitorou.
Qual é o nível de exposição da sua empresa?
Score de risco em 8 perguntas — resultado imediato.
Fazer o score de riscoO custo financeiro antes de alguém perceber
Um banco de médio porte no Brasil levou 11 meses para identificar que drift no modelo de crédito consignado estava aprovando operações acima do perfil de risco adequado. Resultado: carteira com 18% de inadimplência em segmento que historicamente opera com 6%.
O custo não foi só nas provisões. Foi em capital regulatório imobilizado, em custo de cobrança e em repricing forçado de novas operações.
A causa técnica era simples: o modelo tinha sido treinado em dados pré-pandemia. O comportamento de crédito do tomador de consignado mudou. Ninguém retreinou. Ninguém monitorou a distribuição dos scores ao longo do tempo.
Onze meses de drift custaram mais do que dois anos de governança teria custado.
O padrão se repete em antifraude, em precificação e em churn prediction. O custo acumulado de decisões ruins tomadas por modelo degradado supera em ordens de magnitude o custo de detectar e corrigir.
Como detectar antes do dano aparecer
Monitorar drift exige métricas específicas. Não é a mesma coisa que monitorar disponibilidade do sistema.
PSI — Population Stability Index. Mede se a distribuição dos dados de entrada mudou em relação ao período de treino. PSI acima de 0,2 é sinal de drift relevante. É simples de calcular e dá alerta precoce de data drift.
Comparação de distribuição de scores ao longo do tempo. Se o modelo de crédito estava gerando scores entre 400 e 750 e começa a concentrar scores acima de 700 sem que a carteira tenha melhorado, algo mudou.
Monitoramento de métricas de negócio por coorte. Separe os contratos aprovados por período de score. Se a inadimplência de contratos aprovados com score 650–700 em Q1 é sistematicamente maior que em Q4 do ano anterior, o modelo degradou.
Shadow mode. Rode o modelo novo em paralelo com o antigo, sem aplicar as decisões. Compare outputs. Diferença acima de threshold pré-definido dispara revisão.
Nenhum desses controles é sofisticado. Todos exigem que alguém seja responsável por monitorar.
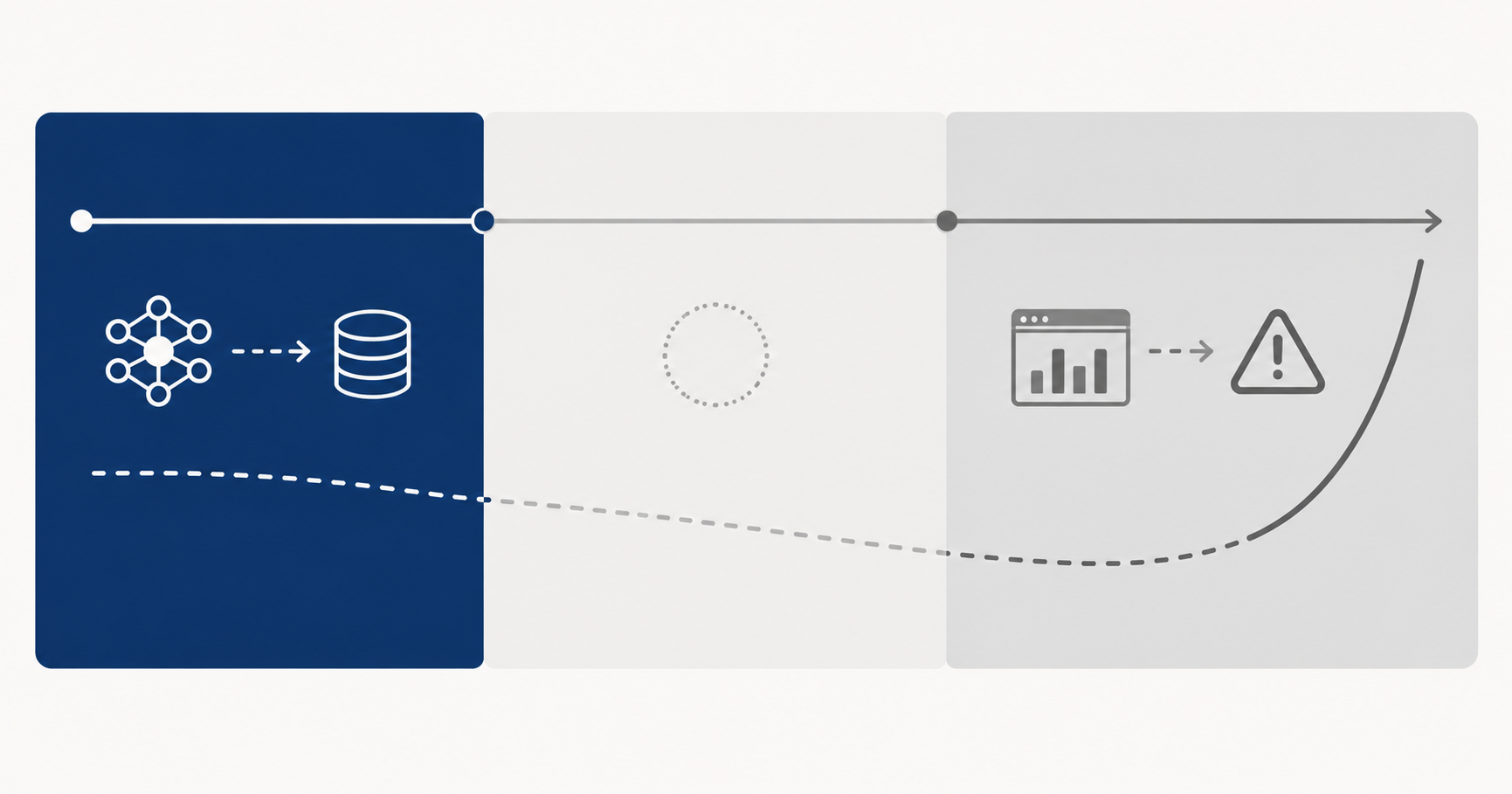
Monitoramento contínuo como controle auditável
O problema de drift não é técnico. É de governança.
Toda empresa com IA em produção precisa de três coisas documentadas:
Definição de baseline. Qual era a performance esperada do modelo no momento do deploy? Quais métricas, quais thresholds, qual frequência de avaliação?
Protocolo de retreinamento. Quando o modelo é retreinado? Quem autoriza? Com quais dados? Qual o critério de aceitação antes de voltar para produção?
Responsável nomeado. Não "a área de dados". Uma pessoa específica que responde pelo comportamento do modelo em produção. Que recebe o alerta. Que escalona se não consegue resolver.
Sem isso, o modelo não tem dono. E modelo sem dono é risco sem controle.
Auditores de ISO 42001 e de SOX pedem exatamente isso: evidência de que o comportamento do modelo é monitorado de forma contínua e rastreável. Não é burocracia. É o mínimo para operar IA com responsabilidade.
Drift já aconteceu. A questão é se você vai descobrir pelo relatório do auditor ou pela DRE.
O score de risco avalia o monitoramento dos seus modelos em produção: alc.ia.br/score-risco.
Para o plano de monitoramento contínuo com responsáveis e prazos: alc.ia.br/diagnostico.